Finding Similar Items (3)- LSH
在上一篇中介紹了可以透過 Minhash 壓縮高維度的資料,找出維度較低的特徵並保留相似性。但僅僅解決了高維度的問題,若資料量很大,仍然以 的時間複雜度進行線性搜尋,還是無法在理想的時間中完成。
因此在本文中會介紹 LSH(Locality-Sensitive Hashing),它的核心概念是 :
若能透過 hashing 的機制,讓相似度高的資料有高機率被 hash 到同一個 bucket 中,相似度低的資料被分到同一個 bucket 的機率很小,那就只需要在同一個bucket中做線性搜尋,就可以找到大多數相似的資料。如此即可將原本大量的資料,分為很多個小的子集合,只需要對子集合中的元素進行運算,進而達到接近 的時間。
Locality-Sensitive Functions
滿足上述的核心概念的hash function 稱之為 Locality-Sensitive Functions,他需要滿足以下兩個條件:
- 若 d(x, y) ≤ d1, 則 f(x) = f(y) 的機率至少為 p1
- 若 d(x, y) ≥ d2, 則 f(x) = f(y) 的機率最多為 p2
其中d(x,y)代表的是x、y的距離,距離越大相似度越小。與上述概念相同,若距離小於d1(相似度高),則hash後的值相同的機率至少為p1,若距離大於d2(相似度低),則hash後的值相同的機率最多為p2。滿足上述兩個條件的function,我們稱之為(d1, d2, p1, p2)-sensitive function。
LSH - Minhash
從上一篇介紹中我們知道:
P(Minhash(x) = Minhash(y)) = Jac(x,y)
因此令 d(x,y) 為Jaccard distance (1-Jaccard similarity),我們可以得到
d(x,y) = 1 - Jac(x,y) ≤ d1
P(Minhash(x) = Minhash(y)) = Jac(x,y) = 1 - d(x,y) ≥ 1 - d1
令 p1 = 1 -d1,即可滿足 P(f(x) = f(y))至少為p1的條件,條件2亦類似。 因此對於Jaccard distance,我們證明了Minhash滿足了Locality-Sensitive Functions的條件,為(d1, d2, 1-d1, 1-d2)-sensitive function。
接下來介紹minhash用作lsh的實際範例: 首先我們先透過 Minhash 取得 signature matrix,並將其分做 b 個 band(bucket),每個 band 中有 r 個 signature。
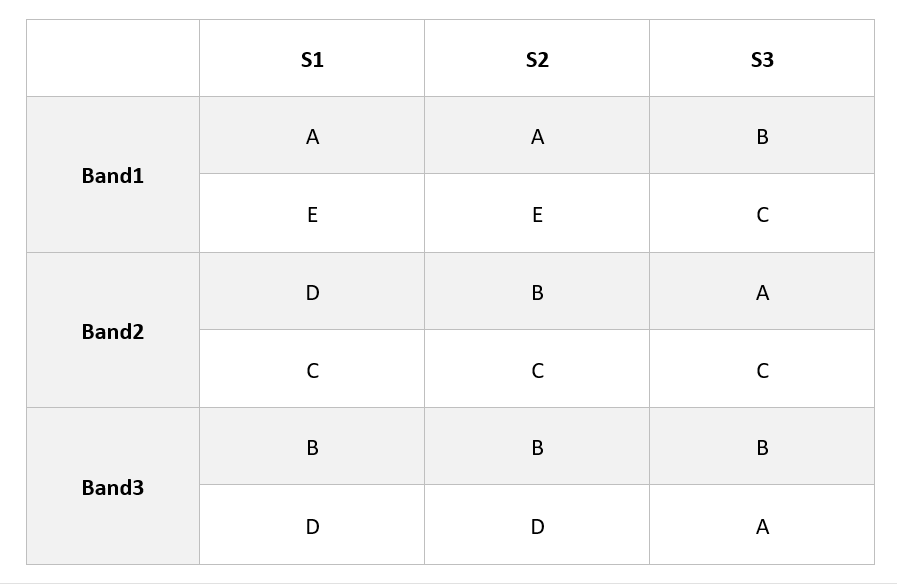 上述範例 b = 3, r = 2
假設 Jac(S1,S2) = P(f(x) = f(y)) = t
任一個 band :
上述範例 b = 3, r = 2
假設 Jac(S1,S2) = P(f(x) = f(y)) = t
任一個 band :
S1 = S2 (全部的 signature 都相等)的機率為
S1 ≠ S2 的機率則為
全部的 band :
S1 ≠ S2 的機率為
至少有一個 band 中 S1 =S2 的機率則為
選定好r跟b,即可產生出t的函數:
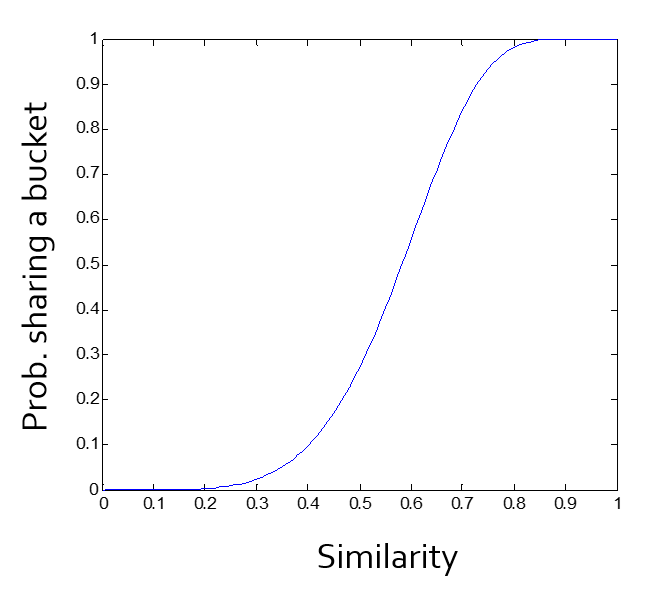 若今天想產生一個(0.3, 0.4, 0.7, 0.6)-sensitive function
只要調整 r 和 b 即可求出對應的S曲線(上圖)
因此即達到目的,可以確保至少在一個區間中會有相同的集合,所以只要遍歷整個hash table,即可找出相似的集合。
若今天想產生一個(0.3, 0.4, 0.7, 0.6)-sensitive function
只要調整 r 和 b 即可求出對應的S曲線(上圖)
因此即達到目的,可以確保至少在一個區間中會有相同的集合,所以只要遍歷整個hash table,即可找出相似的集合。
除了Jaccard distance 與 minhash 外,還有許多不同的距離與相應的LSH,如Cosine distance 與 H(V) = sign(V·R)等,但其概念都是類似的。
最後總結一下 finding similar items: 為了降低搜尋的時間,主要利用:
- Minhash: 利用similarity preserving hashing ,找出低維度且保留相似度的特徵。
- LSH : 透過 hashing 將可能相似的集合放置同一 bucket ,針對buckets 中的 candidate pairs 作比對,即可降低搜尋的時間複雜度。

